08 Oct 2025
Optimizing Github Actions for Git-Mastery
4 min read
I shared this on my Telegram chat!
Background: In Git-Mastery, we track progress locally through a fork of the progress repository, and submit this progress for remote progress tracking (for students to self-assess and educators to track completion rate) through a pull request to the progress repository.
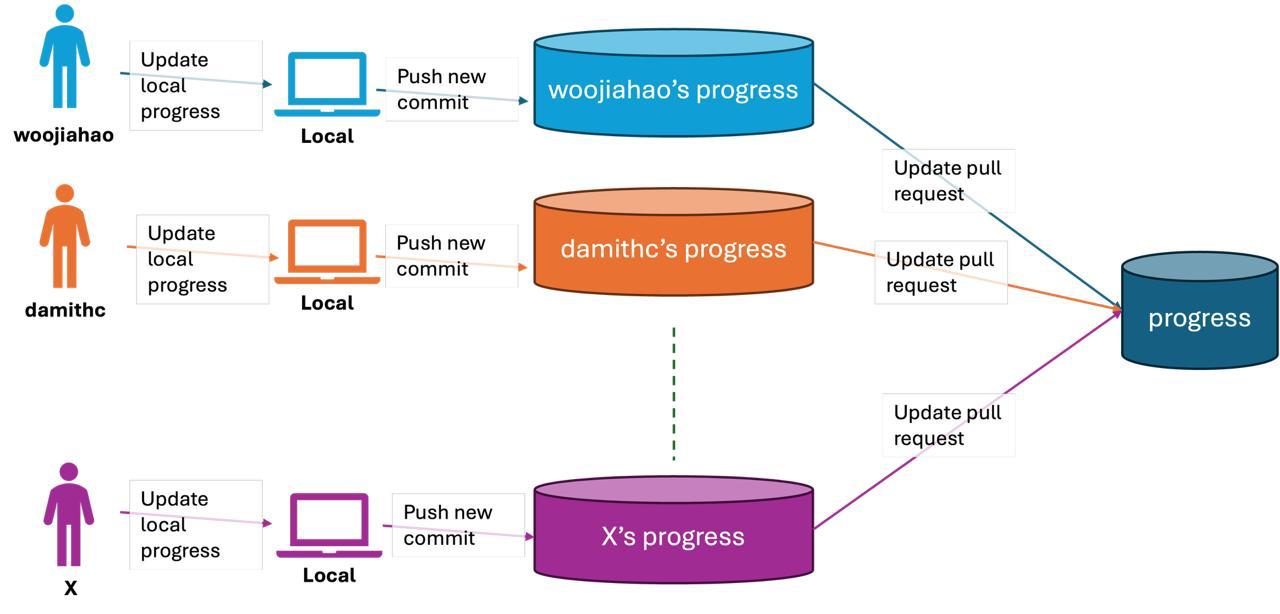
Problem: I have a Github Actions poller scheduled every 30 minutes to sync the progress of students from their PRs to fetch the latest progress they have. This runs lineraly because I didn’t think too hard about scale. The steps can roughly be thought of as
- Fetch all open PRs
- For each PR
- Fetch the latest progress contents
- Store the latest progress contents
- Make any auxiliary file edits and commit them
This scales very poorly with the number of users because we are waiting for every API request for every user, irrespective of whether they did make any new progress. At around 185 users, this poller took 1 minute 30 seconds to run, which is horrible because we’re running this every 30 minutes, every day, which means our Github Actions minutes would be (2 runs/hour * 24 hours/day * 90 seconds/run * 30 days) / 60 seconds = 2160 minutes which greatly exceeds the free 2,000 minutes Github provides. I was not going to pay for the extra minutes used 😭😭
Mitigation measures: I thought of the following to drop this number as low as possible
- Changing the frequency of polling to every hour, effectively halving the minutes used
- Only polling within “awake hours” (e.g. 8am to 8pm), effectively halving the minutes used
- Having some knowledge of last updated progresses to avoid re-downloading every student’s progress every time
- Parallelizing the processing (within Github API’s limits) to speed up processing
Evaluation:
- Likely to cause minimal impact to user experience since they might not be frequently checking their remote progress (since we have local progress tracking too). We can also manually run the pipeline if there’s some urgent need to view the latest data
- Not very feasible because we’re anticipating users around the clock so they might want to view their progress before/after the “awake hours”
- Achievable as we can track the latest commit hash that we saw in the latest sync, which would tell us if there has been any changes to the commits, and only if there were, we can update the file (which saves API calls and processing time)
- Achievable but we have to be very careful as the Github API provides an maximum of 5,000 API calls per hour, so we should avoid spamming the API.
So, I decided to
- Change the frequency to every hour
- “Cache” the latest commit seen for each user
- Parallelize the polling using a ThreadExecutorPool
However, because the “cache” is going to be written by multiple threads, we need to make it thread-safe, so we use a dead simple lock to lock off access to the data structure while reading and writing to it. There may be better ways of doing this but this was what I came to as a quick bandaid for this issue.
The pseudocode is below and it’s very straightforward to reason about as there’s only two critical sections.
UserMap = {} // user_id → username; shared
LatestSyncHashes = LoadSyncHashesFromFile() // user_id → latest commit synced; shared
L = new Lock() // lock for shared data structures
ProcessPr(Pr):
Username = Pr.Username
UserId = Pr.UserId
PrRepo = Pr.Repo
HeadSha = Pr.Head.Sha
L.Lock()
If LatestSyncHashes[UserId] == HeadSha:
UserMap[UserId] = Username
L.Unlock()
Return null
L.Unlock()
Contents = PrRepo.GetContents("progress.json")
WriteJsonToFile("students/" + UserId + ".json", Contents)
L.Lock()
UserMap[UserId] = Username
LatestSyncHashes[UserId] = HeadSha
L.Unlock()
Return Username
ProgressSync():
Prs = FetchOpenPrs()
ProcessedUsers = []
TotalProcessed = 0
Executor = ThreadPoolExecutor(workers=8)
Futures = {} // future -> pr
For Pr in Prs:
Executor.submit(ProcessPr(Pr))
For Future in Completed(Futures):
Username = Future.Result()
TotalProcessed++
If Username != null:
ProcessedUsers.Append(Username)
If HasChanged("students/"):
AddAndCommit("students/")
WriteJsonToFile("user_map.json", UserMap)
WriteJsonToFile("latest_sync_hashes.json", LatestSyncHashes)
If HasChanged("user_map.json"):
AddAndCommit("user_map.json")
If HasChanged("latest_sync_hashes.json"):
AddAndCommit("latest_sync_hashes.json")Using these optimizations, I managed to push the time to process 185 users down from 1 minute 30 seconds to only 20 seconds on average! So it was a 77.8% improvement!
This means that the cost to run this new pipeline is (1 run/hour * 24 hours/day * 20 seconds/run * 30 days) / 60 seconds = 240 minutes! Saving us about 88.9% of the minutes so I’m not going to become a broke boy for maintaining a free project 😭
Code here
Enjoyed reading?
Consider subscribing to my RSS feed or reaching out to me through email!